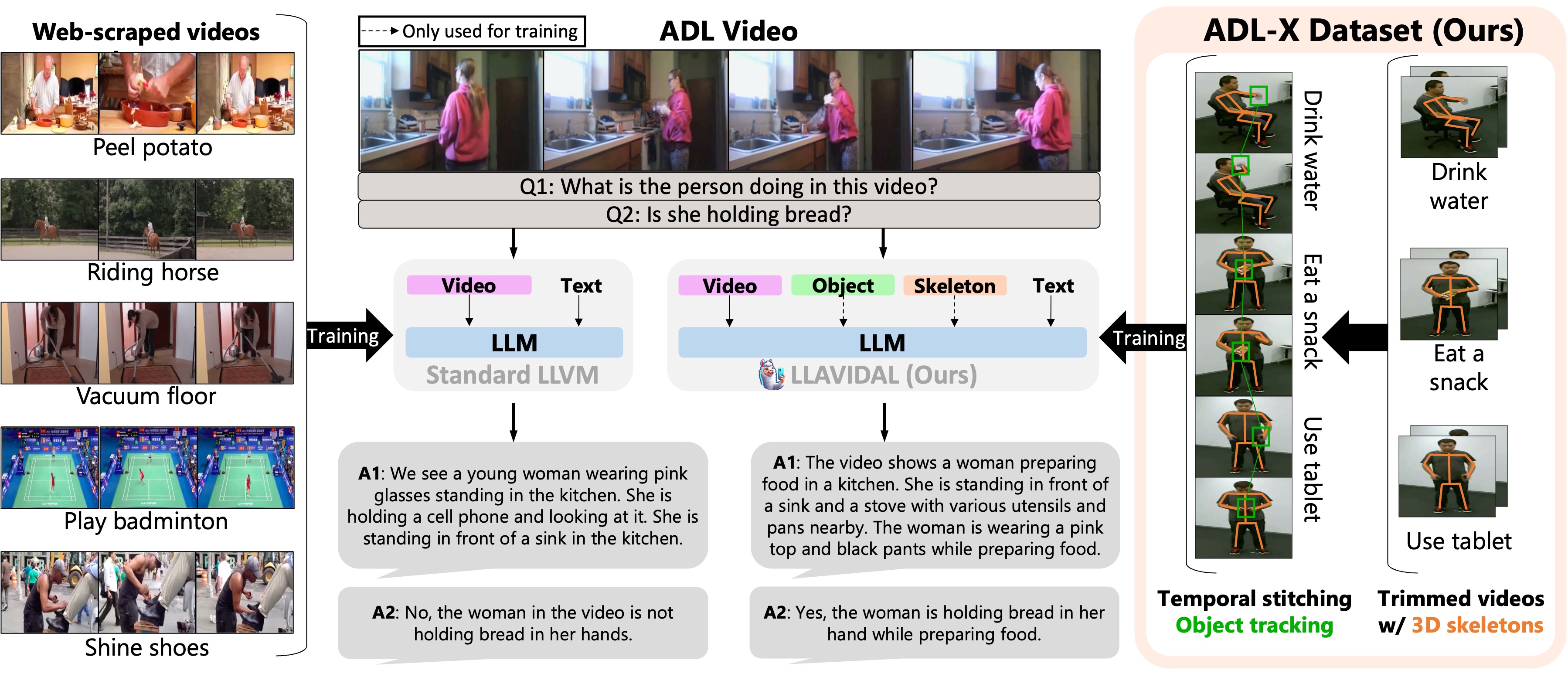
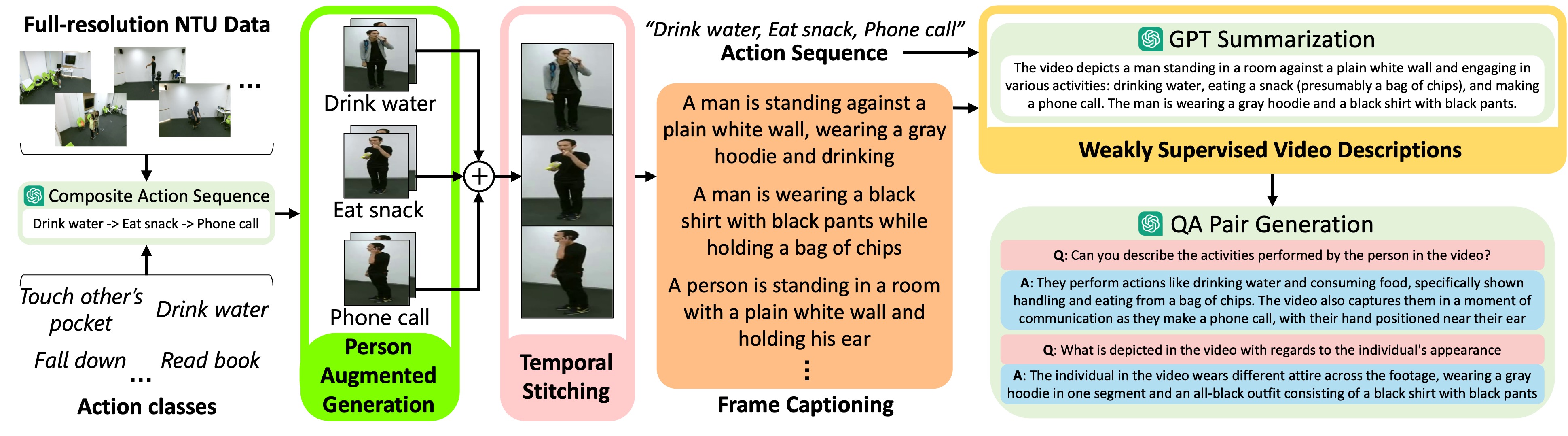
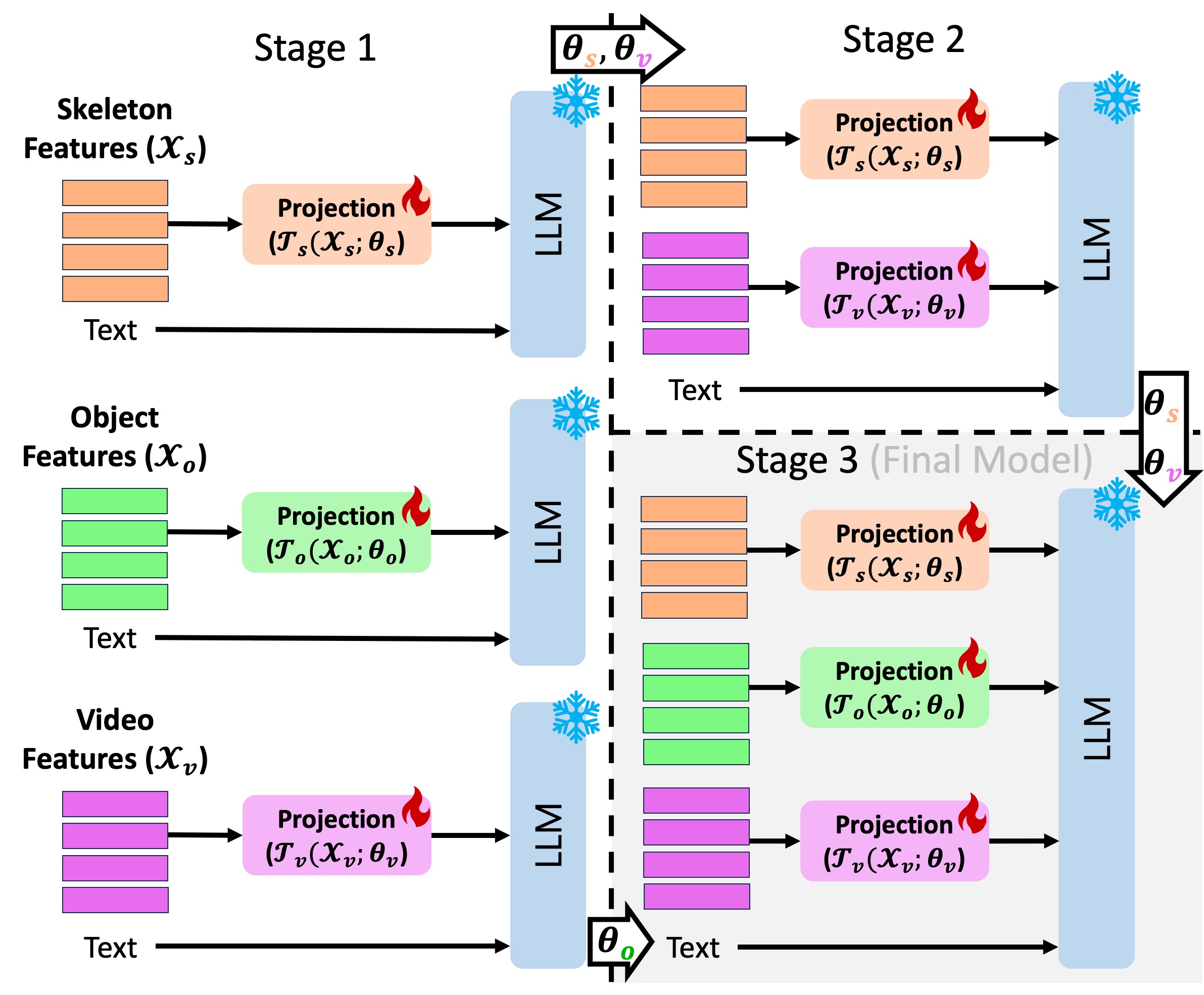
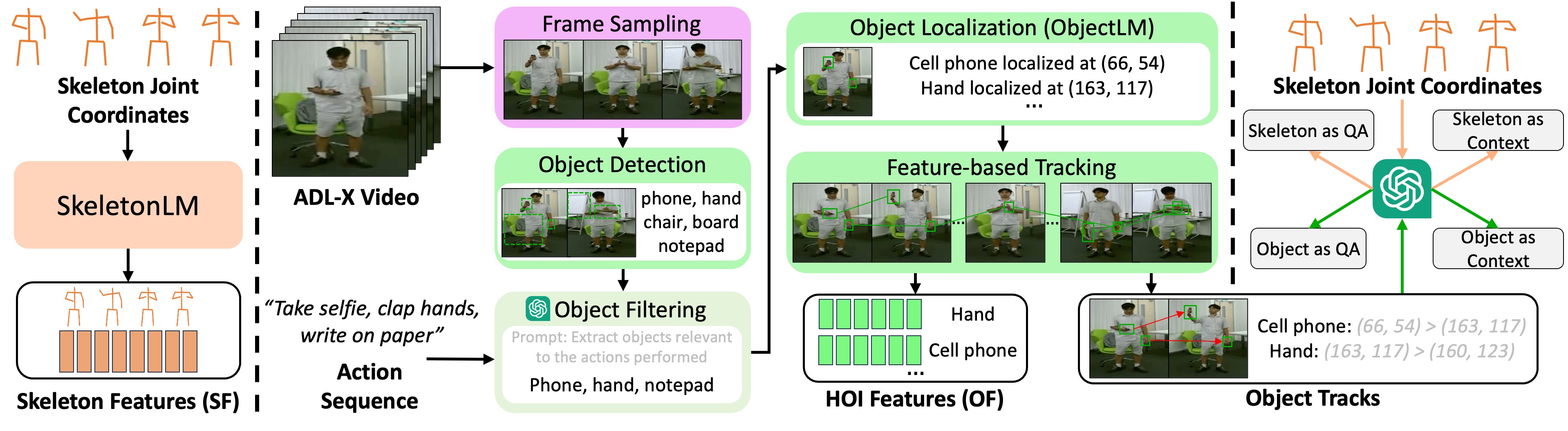
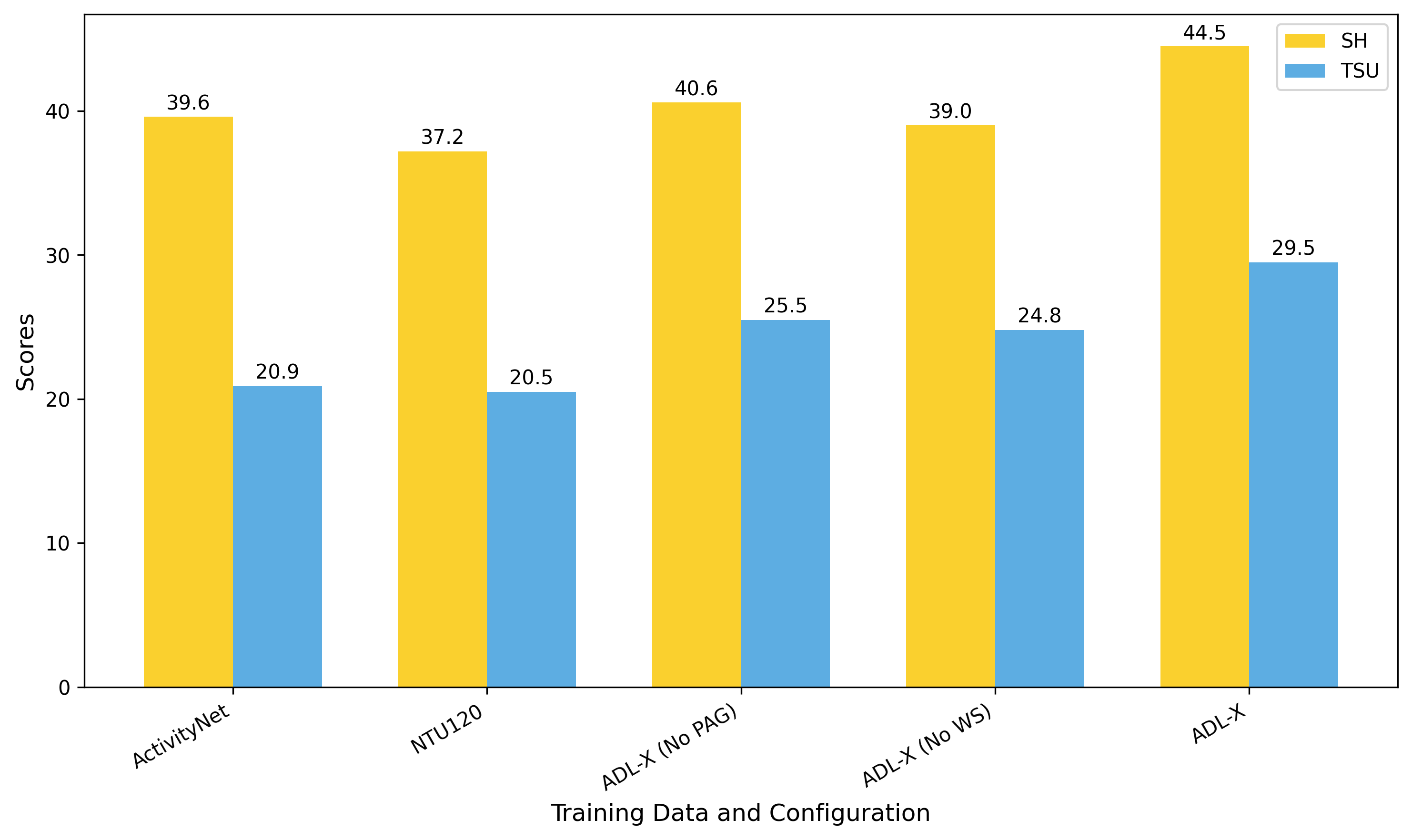
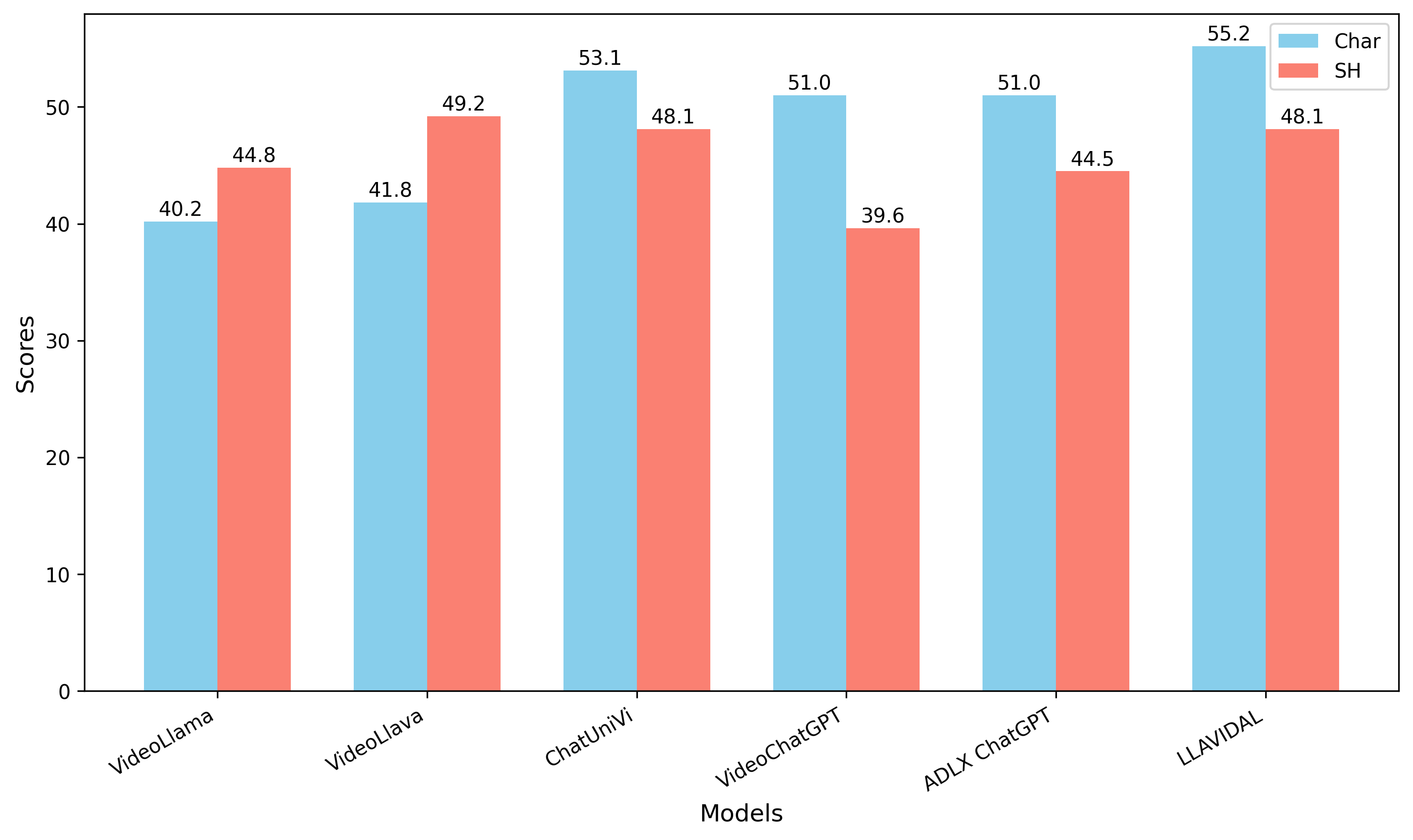
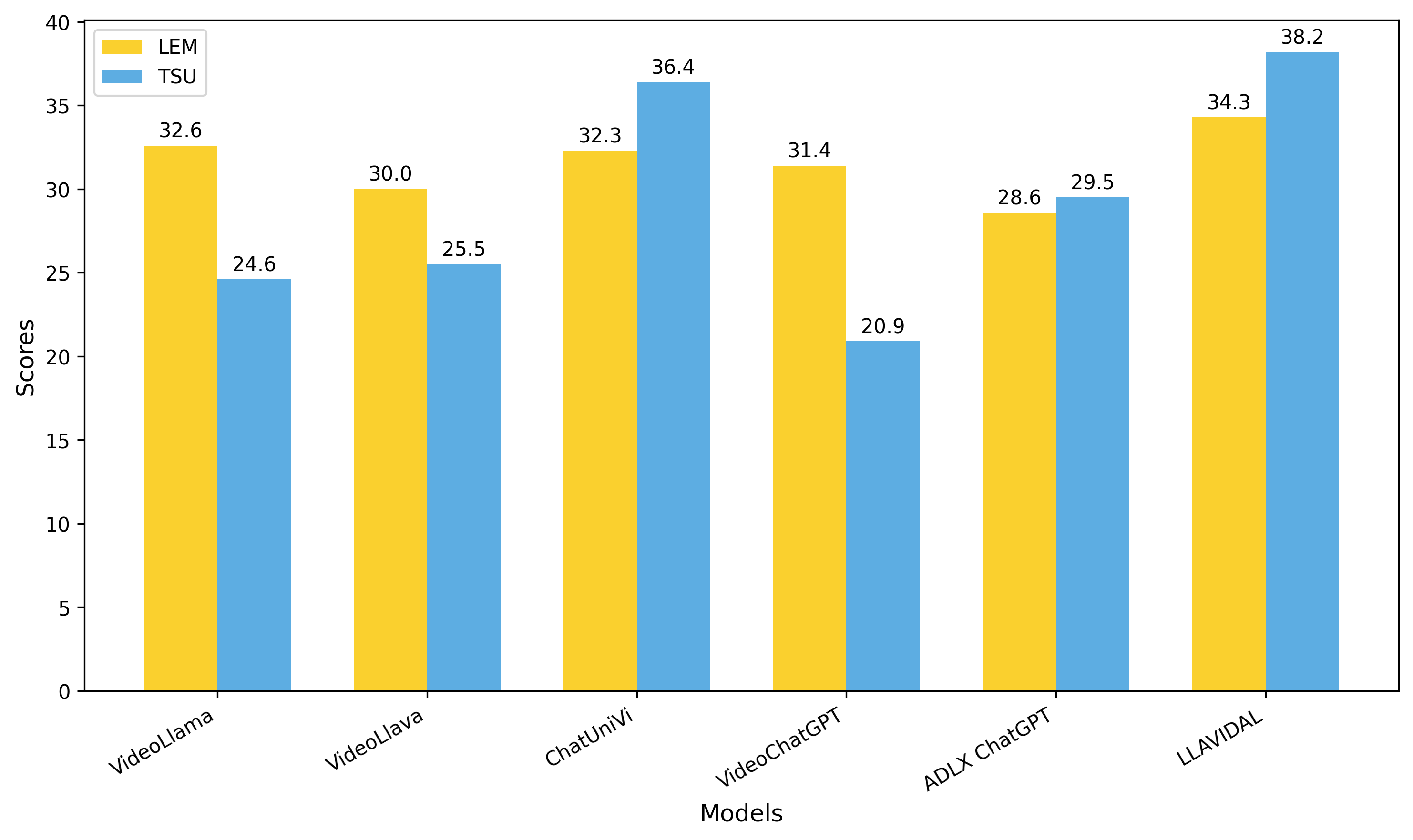
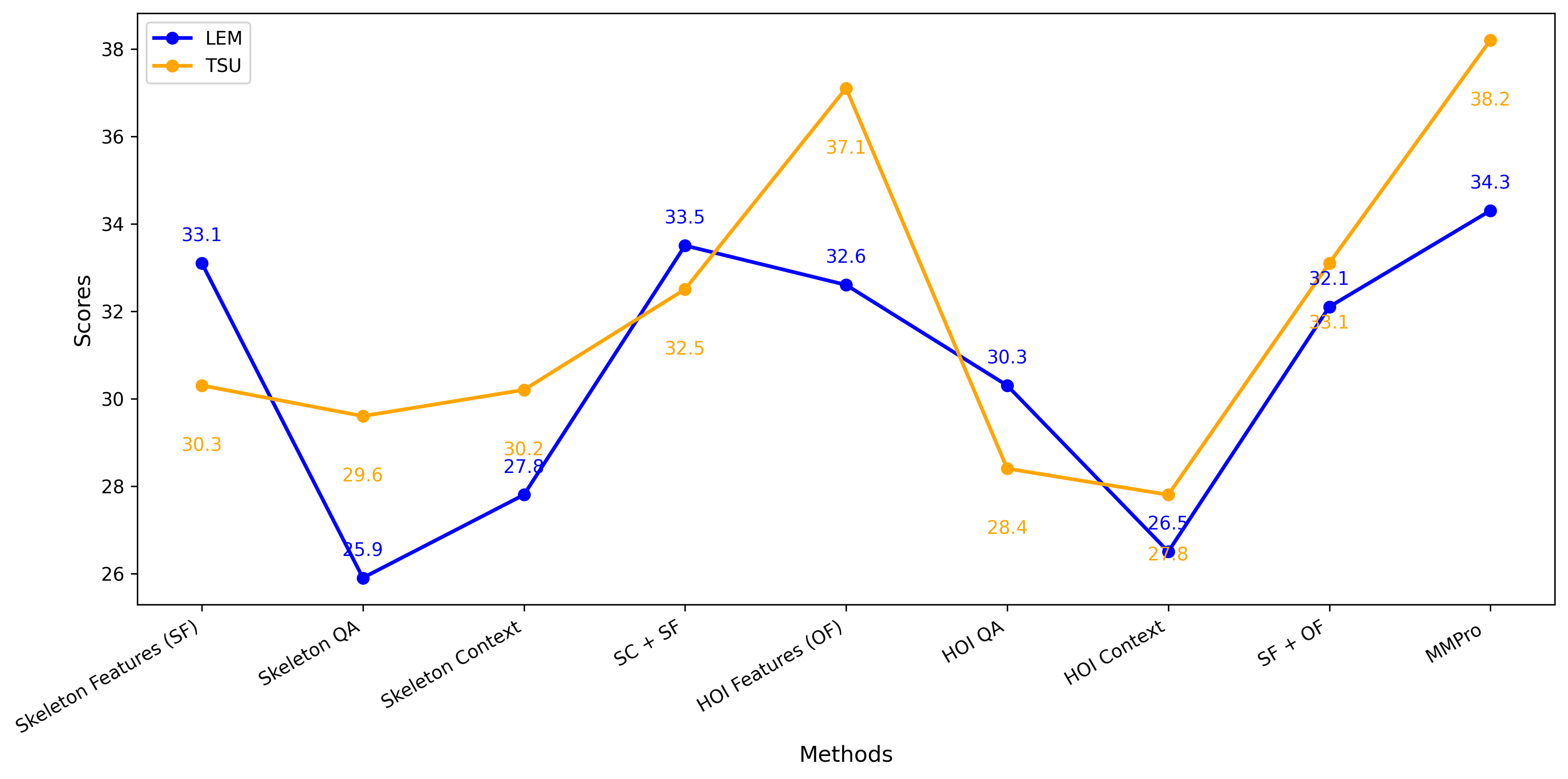
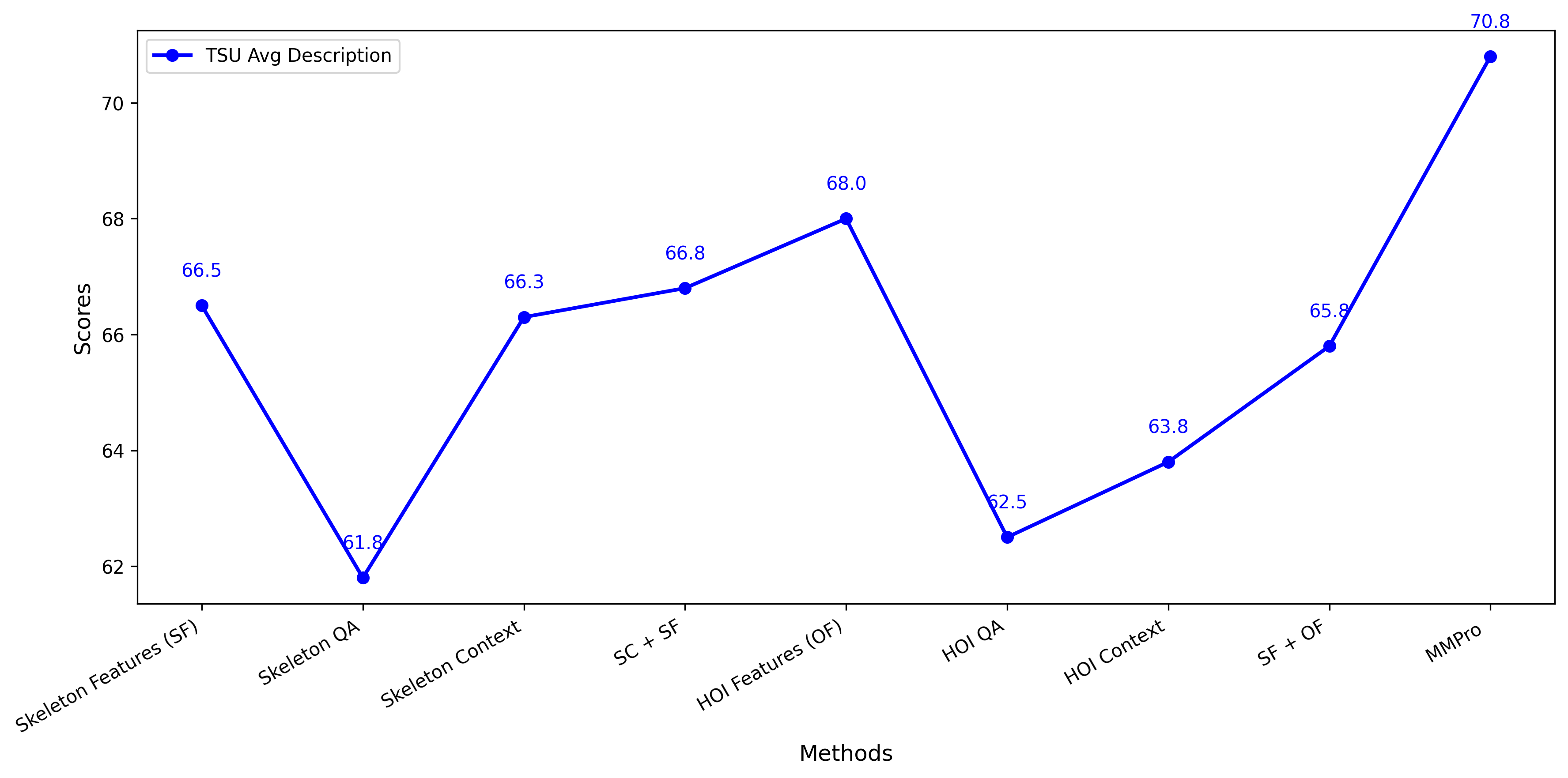
Current Large Language Vision Models (LLVMs) trained on web videos perform well in general video understanding but struggle with fine-grained details, complex human-object interactions (HOI), and view-invariant representation learning essential for Activities of Daily Living (ADL). This limitation stems from a lack of specialized ADL video instruction-tuning datasets and insufficient modality integration to capture discriminative action representations. To address this, we propose a semi-automated framework for curating ADL datasets, creating ADL-X, a multiview, multimodal RGBS instruction-tuning dataset. Additionally, we introduce LLAVIDAL, an LLVM integrating videos, 3D skeletons, and HOIs to model ADL's complex spatiotemporal relationships. For training LLAVIDAL a simple joint alignment of all modalities yields suboptimal results; thus, we propose a Multimodal Progressive (MMPro) training strategy, incorporating modalities in stages following a curriculum. We also establish ADL MCQ and video description benchmarks to assess LLVM performance in ADL tasks. Trained on ADL-X, LLAVIDAL achieves state-of-the-art performance across ADL benchmarks.



@article{llavidal2024,
title={LLAVIDAL: A Large LAnguage VIsion Model for Daily Activities of Living},
author={Dominick Reilly and Rajatsubhra Chakraborty and Arkaprava Sinha and Manish Kumar Govind and Pu Wang and Francois Bremond and Le Xue and Srijan Das},
journal={arXiv},
year={2024},
volume={2406.09390}
}
The dataset is protected under the CC-BY license of Creative Commons, which allows users to distribute, remix, adapt, and build upon the material in any medium or format, as long as the creator is attributed. The license allows ADL-X for commercial use. As the authors of this manuscript and collectors of this dataset, we reserve the right to distribute the data.